
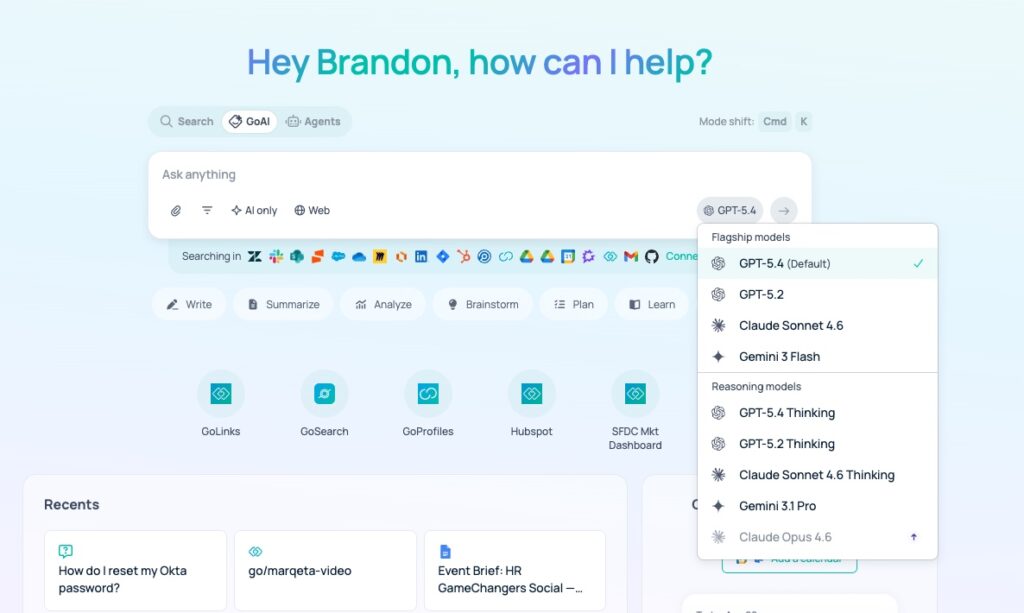
GoSearch now includes GPT-5.4 as a core model option for enterprise search and automation tasks. This update adds OpenAI’s newest flagship model, launched today, to the GoSearch model ecosystem. GPT-5.4 utilizes a discrete “thinking” phase to process multi-step logic before generating a final response. Because of this architectural change, GPT-5.4 handles complex queries with higher technical accuracy than its predecessors. Organizations access this model and other LLMs through GoSearch to interact with their connected data.
Key Takeaways
- GoSearch users can now select GPT-5.4 as the primary model for tasks requiring high-level reasoning and complex data synthesis.
- The GPT-5.4 architecture includes a native thinking process that reduces logical errors in multi-turn agentic workflows.
- GoSearch enables GPT-5.4 to generate structured data formats, including spreadsheets and code, based on internal company documentation.
- The integration maintains existing enterprise data permissions to ensure GPT-5.4 only processes authorized information.
GPT-5.4 Improves Agentic Reasoning in GoSearch
GPT-5.4 improves agentic performance by utilizing an internal chain-of-thought process before executing external tool calls. To achieve this, the model evaluates the necessity of each step within a larger workflow. This reduces the frequency of “hallucinated” API calls in complex environments like Jira or GitHub. Beyond this, GPT-5.4 demonstrates a measurable increase in instruction following for long-context windows. As a result, AI agents maintain focus on the primary objective throughout extended sessions.
Data Synthesis and File Generation: Strengths of GPT-5.4
The implementation of GPT-5.4 in GoSearch facilitates the direct conversion of unstructured data into structured assets. In this scenario, GPT-5.4 parses retrieved data and generates formatted files like CSVs or Google Sheets. Because of this capability, the system automates the transition from raw information to actionable documentation. To ensure accuracy, the model cites specific internal sources for every data point it includes in the generated file.
GPT-5.4 Technical Specification and Impact
| Metric | GPT-5.4 Specification | Functional Impact |
| Logic Processing | Explicit “Thinking” Tokens | Increases accuracy for math and coding tasks. |
| Workflow Depth | High-Horizon Persistence | Enables 10+ step autonomous agent workflows. |
| Tool Integration | Parallel Function Calling | Executes multiple data fetches in a single turn. |
| Security Layer | GoSearch RBAC Integration | Limits model visibility to user-authorized files. |
Comparative Model Performance in GoSearch
Organizations use GPT-5.4 via GoSearch to solve problems that exceed the logic capabilities of standard LLMs. This model functions as a specialized engine for high-stakes reasoning rather than simple conversational Q&A. To manage operational complexity, GoSearch allows administrators to route simple queries to smaller models. This routing ensures that the high-latency reasoning of GPT-5.4 is leveraged for complex tasks. This strategy balances system responsiveness with deep analytical power.
GPT-5.4 Deployment Trade-offs and Latency Considerations
Deploying GPT-5.4 requires a trade-off between the depth of the reasoning process and the speed of the output. The model’s internal verification steps add several seconds to the initial response time. To mitigate this impact, GoSearch provides real-time status updates during the “thinking” phase. Users see when GPT-5.4 is researching, planning, or verifying its steps. Because of this transparency, teams can monitor the progress of long-running autonomous tasks without manual intervention.
Technical Comparison: GPT-5.4 vs. Gemini 3.1 Pro for Coding Tasks
Both GPT-5.4 and Gemini 3.1 Pro are popular models for reasoning and coding. The following table compares the specific technical performance of GPT-5.4 and Gemini 3.1 Pro within the GoSearch ecosystem. These benchmarks focus on agentic coding, software engineering behavior, and long-context repository analysis.
| Feature / Benchmark | GPT-5.4 | Gemini 3.1 Pro | Developer Impact |
| SWE-Bench Pro | 57.2% (Projected) | 54.2% | GPT-5.4 leads in resolving complex, real-world GitHub issues. |
| LiveCodeBench (Elo) | 2840 (Projected) | 2887 | Gemini 3.1 Pro excels in competitive programming and algorithmic logic. |
| Context Window | 1,000,000 Tokens | 1,048,576 Tokens | Both models support analyzing entire medium-to-large repositories. |
| “Thinking” Architecture | Native Logic Planning | Optional “High” Thinking Mode | GPT-5.4 prioritizes step-by-step verification; Gemini prioritizes speed. |
| Agentic Coding | Integrated Codex 5.3 | Custom Tools Endpoint | GPT-5.4 is more autonomous; Gemini offers more granular tool control. |
| Output Token Limit | 128,000 Tokens | 65,536 Tokens | GPT-5.4 can generate significantly longer scripts and full-file refactors. |
GPT-5.4 vs Gemini 3.1 Pro for GoSearch Users
Organizations choosing between these two models for coding workflows face a trade-off between algorithmic precision and autonomous execution. Luckily, both models are available in GoSearch to select which is best suited to every query or task.
- Select GPT-5.4 for autonomous agentic workflows. Its integration of gpt-5.3-codex capabilities and native computer control makes it superior for tasks that require the AI to navigate multiple files, run terminal commands, and verify its own results without human intervention. Because of its higher output token limit, it is more effective for generating comprehensive technical documentation or refactoring large modules in a single pass.
- Select Gemini 3.1 Pro for complex algorithmic development and rapid prototyping. It holds the current top spot in the LiveCodeBench Elo ratings, indicating a stronger grasp of abstract logic and competitive coding problems. Beyond this, Gemini’s dedicated “customtools” endpoint allows developers to force-prioritize specific internal tools (like view_file or search_code), which provides more predictable behavior during interactive “vibe coding” sessions.
Frequently Asked Questions About GPT-5.4 in GoSearch
How does GPT-5.4 differ from previous models in GoSearch?
GPT-5.4 introduces a dedicated reasoning phase that allows the model to verify its own logic before outputting a response. This architectural change makes it significantly more effective for complex technical tasks, such as debugging code or performing multi-step data audits across various enterprise applications.
What specific agentic tasks can GPT-5.4 perform?
GPT-5.4 can plan and execute multi-step workflows, such as retrieving project updates from Slack, cross-referencing them with Jira tickets, and drafting a status report. To complete these tasks, the model breaks down the user’s goal into smaller, logical sub-tasks and executes them sequentially.
How does GoSearch ensure data privacy with GPT-5.4?
GoSearch routes all GPT-5.4 queries through a secure enterprise gateway that prevents the use of internal data for model training. The system also enforces Role-Based Access Control (RBAC), ensuring the model only analyzes files and records that the specific user has permission to access.
Can GPT-5.4 generate technical documentation and code?
Yes, GPT-5.4 features enhanced capabilities for producing structured technical content and functional code snippets. It utilizes the context found within your GoSearch-connected repositories to ensure that any generated code or documentation aligns with your organization’s existing internal standards and libraries.
When should you choose GPT-5.4 over other models?
Users should select GPT-5.4 for tasks that require high logical precision, mathematical reasoning, or the coordination of multiple software tools. While standard models work for simple information retrieval, GPT-5.4 is the preferred choice for synthesizing disparate data points into a cohesive, high-authority output.
Search across all your apps for instant AI answers with GoSearch
Schedule a demo




